
A/B 测试作为一种科学评估 AI 系统性能的方法论,正在重塑机器学习模型的迭代与部署流程从早期互联网公司的页面优化实验,到现代大语言模型的 Prompt A/B 测试,这一技术经历了从简单分流到复杂自适应算法的演进。
本文将深入剖析 AI A/B 测试的完整技术演进脉络,揭示其背后的统计原理、工程实践与产业变革核心观点:这不仅是技术演进的编年史,更是数据驱动决策文化的形成史AI A/B 测试的发展历程告诉我们:真正的智能迭代,源于科学的实验设计与严谨的因果推断。
本文适合读者:AI/ML工程师、产品经理、数据科学家、技术管理者、研究人员
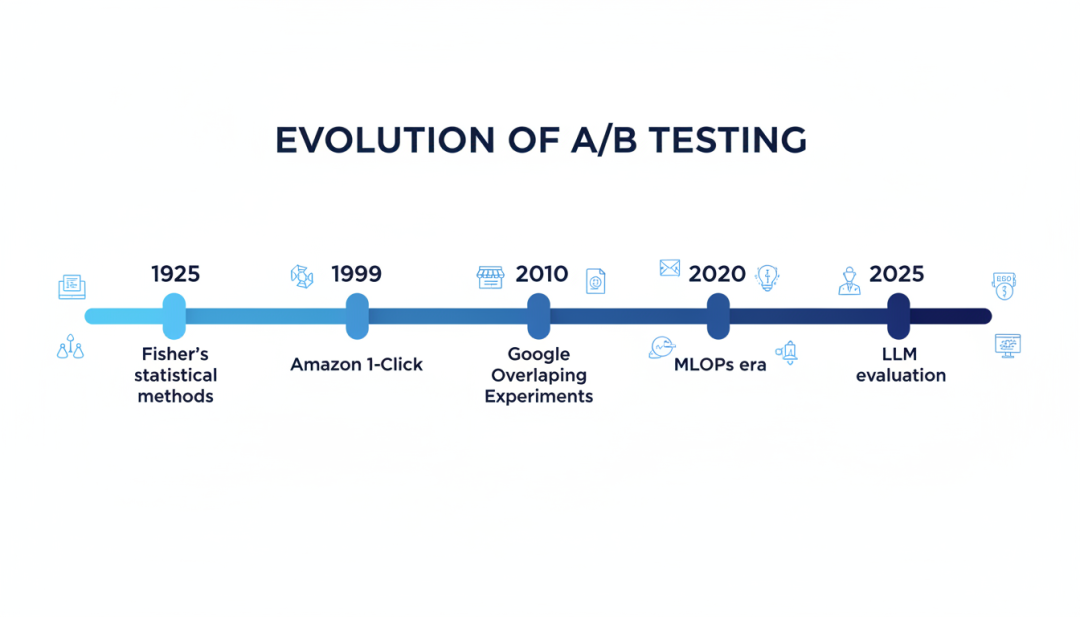
▲ A/B测试从1925年费舍尔统计理论到2026年LLM评估的演进历程一、实验精神的觉醒——A/B 测试的起源1.1 统计假设检验的百年传承A/B 测试的数学基础可以追溯到 20 世纪初的统计推断理论。
1925 年,英国统计学家罗纳德·费舍尔(Ronald Fisher)在其经典著作《Statistical Methods for Research Workers》中奠定了现代统计方法的基础1935 年。
,他在《实验设计》中系统阐述了随机化实验的原则,并提出了著名的”女士品茶”实验费舍尔的核心贡献:随机化原则:通过随机分配消除混杂因素的影响零假设显著性检验(NHST):建立假设-实验-推断的科学范式方差分析(ANOVA)
:比较多组差异的统计方法20 世纪 30 年代,耶日·奈曼(Jerzy Neyman)和卡尔·皮尔逊(Karl Pearson)进一步完善了假设检验理论,提出了备择假设、第一类错误(α)和第二类错误(β)的概念,构建了现代假设检验的完整框架。
1.2 互联网时代的 A/B 测试萌芽1990 年代末,随着互联网的兴起,A/B 测试开始从实验室走向商业应用Amazon 的“一键下单”专利(1999)1997 年,Amazon 申请了著名的”一键下单”(1-Click)专利,并于 1999 年获得授权。
Amazon 通过 A/B 测试发现,减少结账步骤可以显著提升转化率这个案例成为互联网 A/B 测试的经典范例Google AdWords 的实验雏形2000 年代初,Google 开始在其广告系统中使用简单的实验方法。
工程师们发现,即使是微小的界面改动,也可能对点击率和收入产生显著影响这种”数据说话”的文化逐渐在 Google 内部形成早期 A/B 测试的局限性:流量限制:早期网站流量有限,难以在合理时间内获得统计显著的结论
工具原始:缺乏专门的实验平台,工程师需要手动编写分流代码指标单一:主要关注点击率、转化率等简单指标分析滞后:数据收集和分析周期长,实验反馈慢1.3 从页面优化到产品决策2000 年代初,A/B 测试开始从简单的页面优化扩展到更广泛的产品决策场景。
转化率优化(CRO)的兴起随着电子商务的发展,”转化率优化”(Conversion Rate Optimization, CRO)成为一门独立的学科A/B 测试成为 CRO 的核心工具,用于优化着陆页、表单设计、定价策略等。
数据驱动决策的文化建立Netflix 的推荐算法实验:2006 年,Netflix 举办了著名的推荐算法竞赛(Netflix Prize),悬赏 100 万美元寻找能够将推荐准确度提升 10% 的算法LinkedIn 的社交功能实验
:通过 A/B 测试优化其”你可能认识的人”功能,显著提升了用户连接数eBay 的搜索排序实验:通过 A/B 测试不断优化其搜索排序算法,平衡买家体验和卖家利益从传统 A/B 测试到 AI A/B 测试的演进
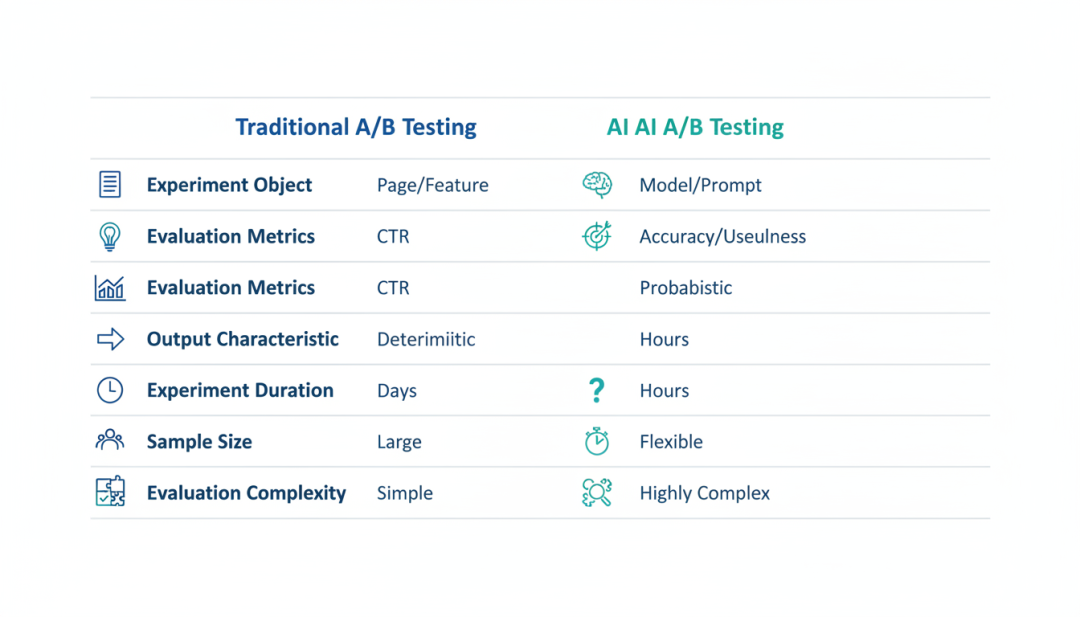
▲ 传统A/B测试与AI A/B测试的对比
二、规模化实验平台——工业级 A/B 测试的崛起2.1 Google 的 Overlapping Experiment Infrastructure2010 年,Google 在 KDD 会议上发布了《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》论文,标志着工业级 A/B 测试平台的诞生。
分层实验架构的核心思想Google 面临的问题是:每天有数百个实验同时运行,如何确保这些实验不会相互干扰?解决方案是分层实验架构(Layered Experimentation)想象一个网站有多个可以独立修改的组件:UI 层、搜索算法层、广告排序层、推荐层等。
每一层可以独立运行多个实验,而不同层之间的实验可以”重叠”——即一个用户可以同时参与多个层的不同实验
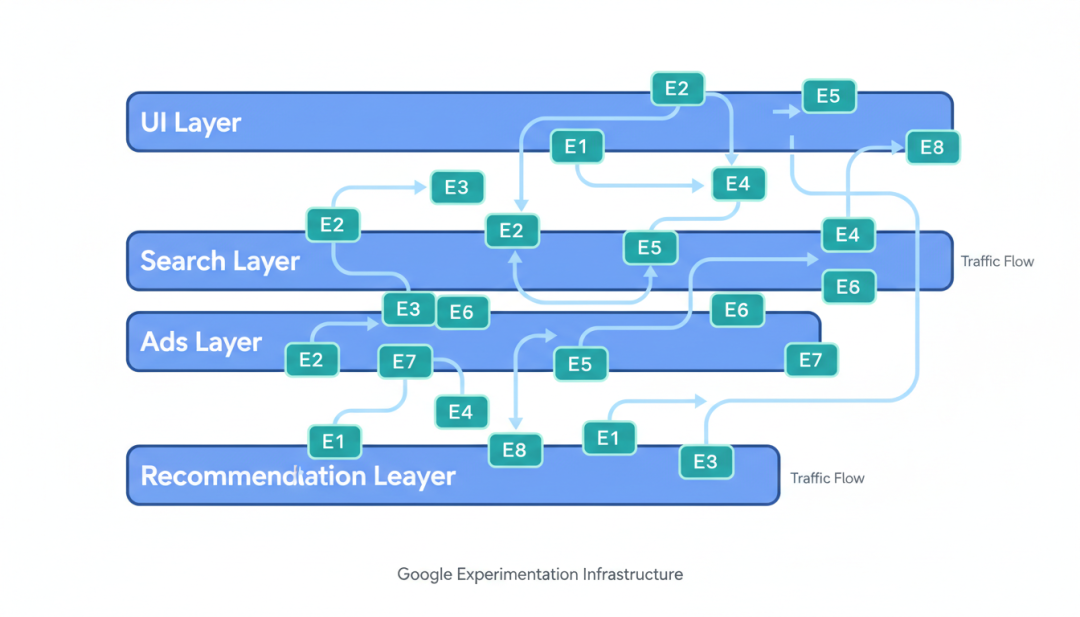
▲ Google分层实验架构示意图重叠实验的数学原理假设有 L 个实验层,每层可以运行多个实验对于用户 u,其在每层 l 的实验分配可以表示为:Assignment(u, l) = Hash(u, l) mod Nl。
其中,Nl是第 l 层的实验数量这种基于哈希的分配方法确保了:一致性:同一用户在同一层总是被分配到同一实验组正交性:不同层的分配是独立的均匀性:流量在各实验组间均匀分布Google 实验平台的影响实验数量从每月几十个增加到每月数千个。
实验周期从数周缩短到数天数据驱动决策成为 Google 的核心文化2.2 Microsoft Bing 的实验文化如果说 Google 建立了实验平台的技术框架,那么 Microsoft Bing 则将实验文化推向了新的高度。
Ron Kohavi 与 Bing 实验平台Ron Kohavi 是 Microsoft 的杰出工程师,被誉为”在线实验之父”他在 Bing 领导建立了一套完整的实验生态系统:ExP(Experimentation Platform)。
:统一的实验平台Controlled Experiments:严格的实验设计规范Trustworthy Online Controlled Experiments:实验可信度评估框架“每行代码都需要实验验证”的理念
在 Bing,任何代码改动都需要通过 A/B 测试验证这一文化的形成经历了漫长的过程:初期阻力:工程师认为实验 slows down development成功案例:通过实验发现并修复了多个”直觉上正确但实际有害”的改动。
文化转变:实验成为开发流程的标准环节Bing 实验平台的创新CUPED 技术:Controlled-experiment Using Pre-Experiment Data,方差缩减技术,可将实验灵敏度提升 50% 以上
Sequential Testing:允许在实验过程中”偷看”结果,而不增加假阳性率Long-term Effect Estimation:评估实验的长期影响,避免短期优化损害长期利益2.3 Netflix 的推荐系统实验
Netflix 是 A/B 测试在推荐系统领域的标杆企业从 DVD 邮寄到流媒体的转型2007 年,Netflix 推出流媒体服务与 DVD 业务不同,流媒体允许实时收集用户行为数据,为在线实验创造了条件。
推荐算法的持续实验迭代Netflix 的推荐系统涉及多个组件,每个组件都有独立的实验:召回层:从海量内容中筛选候选集排序层:对候选集进行精排多样性:平衡相关性和多样性解释:为推荐结果生成解释第三章:统计方法的演进——从 Frequentist 到 Bayesian
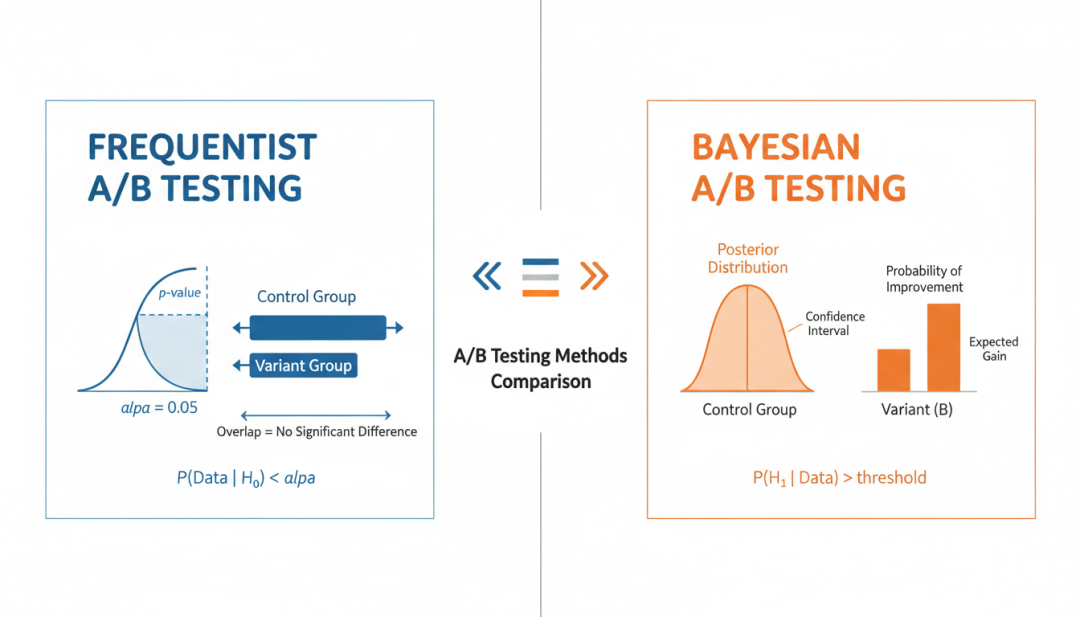
3.1 经典 Frequentist 方法Frequentist 方法是传统 A/B 测试的统计基础,其核心思想是:通过重复抽样来估计参数的分布零假设显著性检验(NHST)A/B 测试的标准流程:1. 建立零假设 H₀:两组无差异(μ_A = μ_B)。
2. 收集数据,计算检验统计量3. 计算 P 值:在 H₀ 成立时,观察到当前或更极端结果的概率4. 如果 P 值 < α(通常 0.05),拒绝 H₀P 值的解读P 值不是“零假设为真的概率”,而是”在零假设为真的前提下,观察到当前数据的概率”。
这是一个常见的误解置信区间95% 置信区间表示:如果重复实验 100 次,约有 95 次的置信区间会包含真实参数统计功效(Power)统计功效 = 1 – β,表示当备择假设为真时,正确拒绝零假设的概率。
通常要求功效 ≥ 80%
▲ Frequentist方法与Bayesian方法的对比3.2 Frequentist 方法的局限性“偷看”问题(Peeking Problem)传统 Frequentist 方法要求实验开始前确定样本量,实验过程中不能查看结果。
然而,这在实际中很难做到:产品经理想知道”实验还要跑多久”;工程师想提前发现”明显有问题”的实验;管理层想知道”目前的趋势如何”如果频繁”偷看”结果并进行决策,会显著增加假阳性率(Type I Error)。
固定样本量的刚性约束如果实验效果比预期好,仍需跑满样本量如果实验效果比预期差,也无法提前止损实验周期可能过长,影响迭代速度无法量化效应大小P 值只告诉我们”是否有差异”,但不能告诉我们”差异有多大”一个统计显著但效应很小的结果,可能没有实际业务价值。
3.3 Bayesian 方法的兴起Bayesian 方法为 A/B 测试提供了新的视角贝叶斯定理P(H|D) = P(D|H) · P(H) / P(D)P(H|D)是后验概率:观察到数据 D 后,假设 H 为真的概率。
P(D|H)是似然:假设 H 为真时,观察到数据 D 的概率P(H)是先验概率:观察数据前,假设 H 为真的概率概率增益(Probability of Improvement)Bayesian A/B 测试的核心指标是”B 优于 A 的概率”:P(μ_B > μ_A | Data)。
这个指标直观易懂:如果 P(μ_B > μ_A) = 95%,意味着有 95% 的把握 B 优于 A可信区间(Credible Interval)与 Frequentist 的置信区间不同,Bayesian 的可信区间有直接的概率解释:”参数有 95% 的概率落在这个区间内”。
3.4 两种方法的对比与选择
大规模实验(如 Google 搜索排序):Frequentist 方法,计算简单,易于并行化小规模实验(如初创公司产品优化):Bayesian 方法,灵活迭代混合方法:使用 Bayesian 方法进行早期筛选,Frequentist 方法进行最终验证
四、方差缩减技术——让实验更高效4.1 实验效率的挑战高方差指标的样本量困境某些指标(如用户留存率、收入)的方差很高,导致:需要大量样本才能检测到小效应;实验周期可能长达数周甚至数月;机会成本高昂4.2 CUPED 技术。
CUPED(Controlled-experiment Using Pre-Experiment Data)是微软在 2010 年代初期提出的方差缩减技术核心思想利用实验前的数据来”解释”实验指标的方差。
如果某些用户的指标在实验前就较高,那么他们在实验期间的表现也可能较高通过控制这种预实验差异,可以减少实验指标的方差
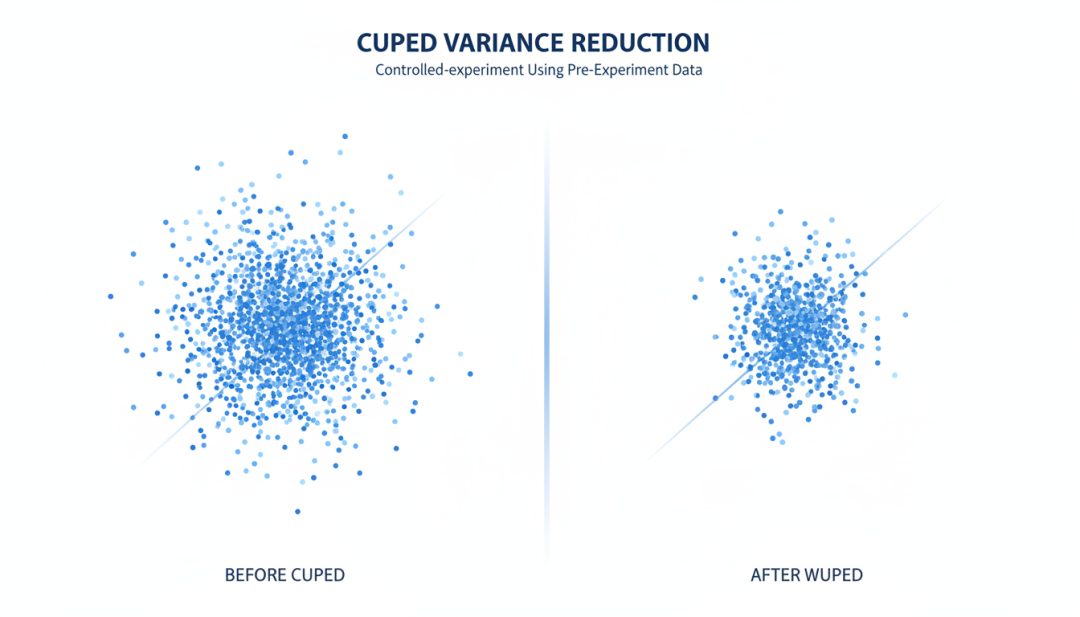
▲ CUPED方差缩减技术原理示意图数学原理设 Y 是实验指标,X 是预实验指标CUPED 调整后的指标为:Y’ = Y – θ(X – X̄)其中,θ 是最优系数,可以通过最小化 Var(Y’) 来求解:。
θ = Cov(Y, X) / Var(X)实际效果40-80%方差降低50-80%样本量减少50%+实验周期缩短实际案例:Bing 搜索实验微软 Bing 在搜索排序实验中应用 CUPED,将实验周期从 2 周缩短到 3 天,同时保持相同的统计功效。
这使得 Bing 能够更快地迭代搜索算法,提升用户体验五、自适应实验——Multi-Armed Bandit5.1 探索与利用的永恒困境A/B 测试的一个根本问题是:探索(Exploration)与利用(Exploitation)的权衡
。

传统 A/B 测试采用”先探索,后利用”的策略这种策略的问题是机会成本:在实验期间,有一半的用户被分配到可能较差的方案,造成潜在损失5.2 Multi-Armed Bandit 算法Multi-Armed Bandit(多臂老虎机)是一种自适应实验方法,可以动态调整流量分配,在探索和利用之间取得平衡。
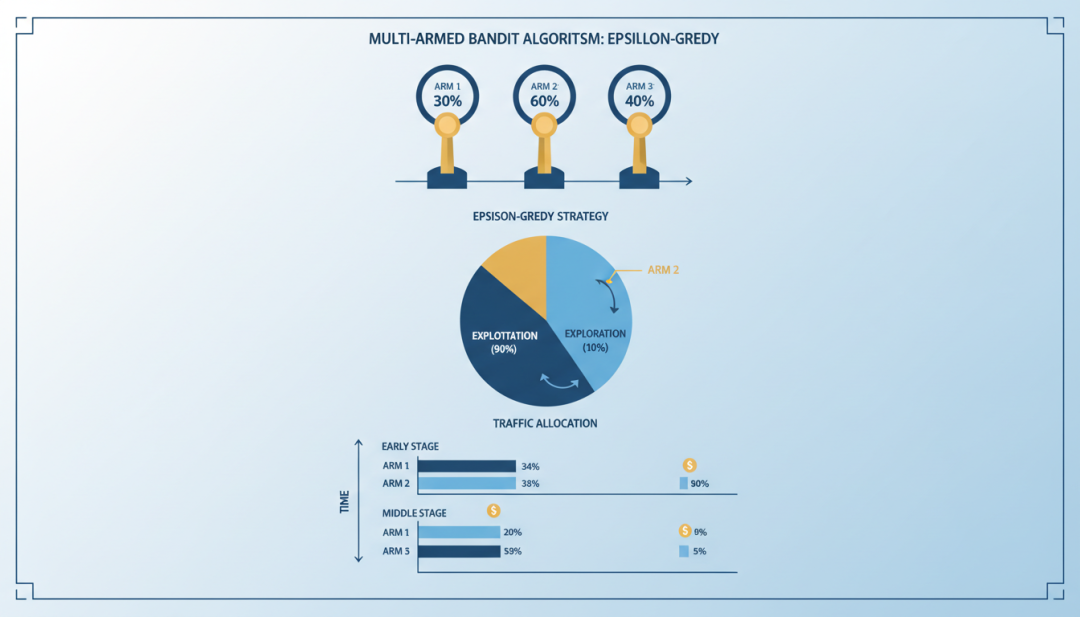
▲ Multi-Armed Bandit算法示意图Upper Confidence Bound (UCB)选择置信上界最高的臂:UCBi= μ̄i+ √(2 ln n / ni)其中,μ̄i是臂 i 的平均收益,n 是总拉动次数,ni是臂 i 的拉动次数。
直观理解:UCB 在估计收益基础上加上一个”探索 bonus”,鼓励尝试拉动次数较少的臂Thompson Sampling为每个臂维护一个收益分布的后验(如 Beta 分布)每次从各臂的后验中采样一个值。
选择采样值最高的臂5.3 Bandit 在 AI 中的应用推荐系统的在线学习新用户冷启动:使用 Bandit 快速学习用户偏好内容探索:平衡热门内容和新内容的推荐实时反馈:根据用户即时反馈调整推荐策略广告竞价优化
出价策略:动态调整出价,平衡探索新策略和利用已知好策略创意优化:自动选择表现好的广告创意

六、搜索与排序的实验——Interleaving 与 Counterfactual6.1 搜索排序实验的特殊性位置偏置(Position Bias)用户更倾向于点击排名靠前的结果,即使靠后的结果更相关这使得简单的点击指标无法准确反映排序质量。
6.2 Interleaving 技术Interleaving 是一种快速比较两个排序算法的方法,由 Chapelle 等人于 2012 年提出核心思想将两个排序算法的结果交错合并,形成一个混合列表展示给用户。
通过观察用户在混合列表上的点击行为,可以推断出哪个算法更好

▲ Interleaving搜索排序比较技术平衡交错(Balanced Interleaving)从两个算法各取一个结果,交替放入混合列表记录用户点击统计每个算法的点击数点击数多的算法获胜6.3 Interleaving 的优势
50x灵敏度提升用户内比较消除个体差异快速筛选候选算法6.4 Counterfactual EvaluationCounterfactual Evaluation(反事实评估)是一种利用历史日志数据评估新算法的方法。
逆倾向评分(IPS)估计器R̂(π) = (1/n) Σu[π(iu|u) / π₀(iu|u)] · ru其中:π 是新策略,π₀ 是日志生成策略,π(i|u) 是策略给用户 u 展示项目 i 的概率,ru是用户的奖励。
七、MLOps 时代的模型实验7.1 机器学习模型的实验需求

7.2 Shadow Deployment(影子部署)Shadow Deployment 是一种在生产环境中测试新模型的方法,不影响真实用户概念与原理新模型(影子模型)接收与生产模型相同的输入影子模型的输出被记录,但不返回给用户。
比较影子模型和生产模型的输出差异评估影子模型的性能和业务影响
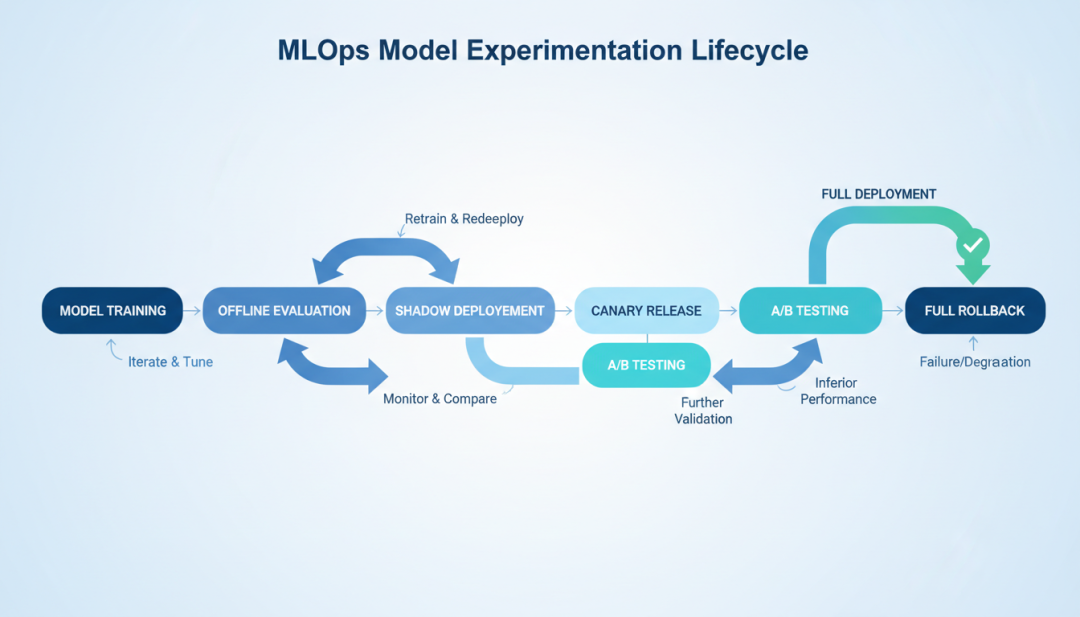
▲ MLOps模型实验生命周期流程与 A/B 测试的互补关系Shadow Deployment:验证模型的技术正确性,无业务风险A/B 测试:验证模型的业务价值,有业务风险7.3 Canary Deployment(金丝雀发布)
Canary Deployment 是一种渐进式发布策略,逐步将流量切换到新模型。渐进式流量切换1%→5%→10%→25%→50%→100%7.4 模型实验的指标体系

八、大语言模型的 A/B 测试8.1 LLM 实验的新挑战非确定性输出与传统软件不同,LLM 的输出是概率性的相同的输入可能产生不同的输出,这使得传统的 A/B 测试方法难以直接应用评估的主观性什么是“好”的回答?。
如何量化“有用性”、“创造性”、“准确性”?不同评估者可能有不同的标准Prompt 工程的复杂性微小的 Prompt 改动可能导致输出大幅变化Prompt 版本管理困难Prompt 组合爆炸
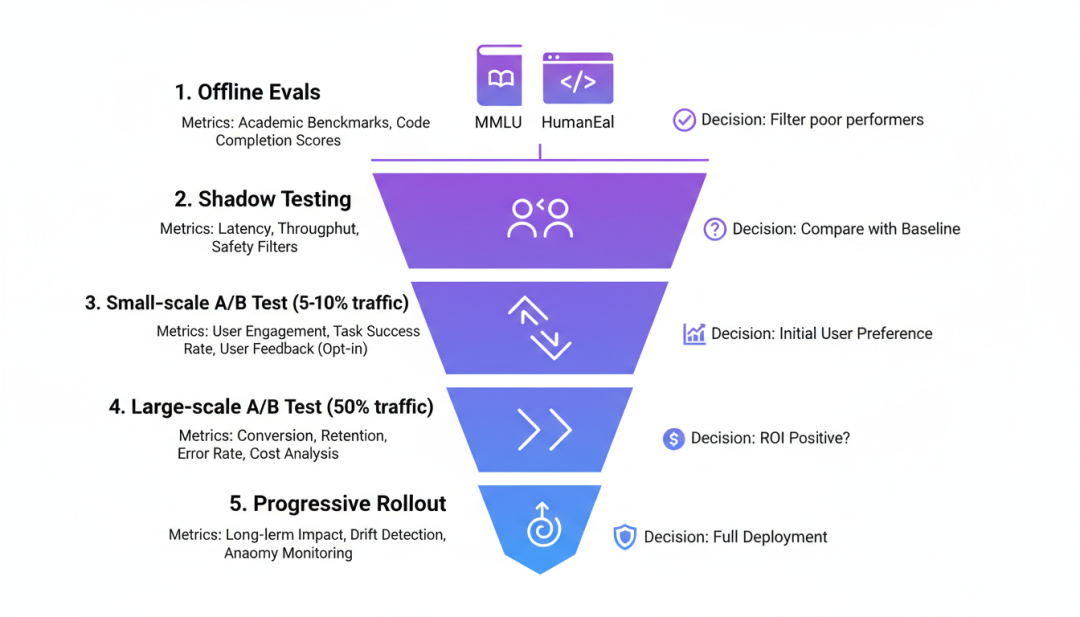
▲ LLM评估漏斗:从离线评估到渐进发布8.2 Prompt A/B 测试Prompt A/B 测试是 LLM 开发的核心环节。

Prompt A/B 测试实际案例背景:某公司使用 xxx模型 构建客服聊天机器人对照组:”你是一个客服助手,请回答用户的问题”实验组:”你是一个友好、专业的客服助手请用简洁、易懂的语言回答用户的问题如果不知道答案,请诚实告知。
”+13%用户满意度+10%问题解决率-27%对话轮数-47%重复询问率8.3 LLM-as-a-JudgeLLM-as-a-Judge 是一种使用 LLM 评估 LLM 的方法。
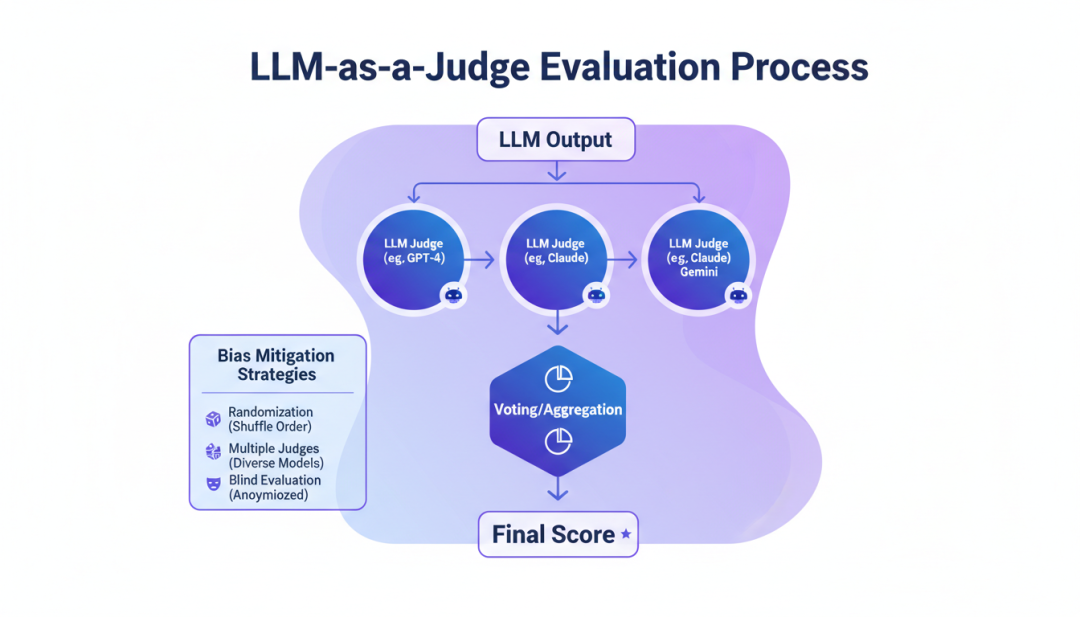
▲ LLM-as-a-Judge评估流程使用一个 LLM(如 GPT-4)作为“评委”评委 LLM 根据预设的评分标准评估被测 LLM 的输出评分标准可以是:准确性、有用性、安全性等评估者的偏差问题自我偏好
:评委 LLM 可能偏好与自己风格相似的输出位置偏置:评委可能受输出顺序影响长度偏置:评委可能偏好更长的输出缓解策略使用多个评委 LLM,取平均或多数投票随机化输出顺序对输出长度进行归一化九、实验平台的架构演进
9.1 实验平台的组件

9.2 工程架构演进
▲ 实验平台架构从2000s到2025+的演进

十、AI 实验的最佳实践与陷阱10.1 实验设计的黄金法则

10.2 常见陷阱Simpson 悖论:整体数据显示 A 优于 B,但在各子群体中 B 优于 A这通常是由于子群体间的基线差异造成的幸存者偏差:只分析”幸存”下来的用户,忽略了已经流失的用户网络效应:用户之间存在相互影响,导致实验组和对照组不独立。
长期效应 vs 短期效应:实验在短期内显示正向效果,但长期可能有害例如,增加广告展示量短期内提升收入,但长期可能导致用户流失十一、2025-2026——AI A/B 测试的爆发与深化11.1 2025 年:LLM 评估平台的成熟。
2025 年,LLM 评估平台迎来了爆发式增长,形成了完整的评估生态根据 2026 年初的行业报告,LLM 评估已成为 AI 开发的”关键瓶颈”——团队要么盲目发布 Prompt,要么花费数周进行手动测试。

11.2 2025 年:AI Agent 评估的兴起Agent 评估的独特挑战多步推理准确性工具使用有效性状态管理可靠性错误恢复模式成本效率11.3 2025 年:实时 A/B 测试与渐进发布

11.4 2026 年 1-2 月:评估技术的最新进展Conformal Risk Control(共形风险控制):提供基于预定义风险水平的弃权或升级触发器,显著提升模型可靠性和用户信任Self-Evaluating LLMs(自我评估 LLM):。
模型被设计为基于一组内部标准评分自己的输出,实现实时内部反馈Automated Evaluation Agents:专门的 AI Agent 主动运行多步测试场景,模拟复杂用户行为十二、未来展望12.1 自适应实验的智能化。

12.2 AI 辅助的实验分析

12.3 实验与产品化的融合实验即产品:实验平台本身成为产品的一部分,用户可以自主创建和运行实验这种”民主化实验”让产品、运营、市场等团队都能参与实验持续优化的闭环:数据收集→模型训练→实验验证→部署上线→数据收集。
12.4 新兴挑战隐私计算与实验:在保护用户隐私的前提下进行实验,如联邦学习、差分隐私等多模态 AI 的实验评估:同时评估文本、图像、音频、视频等多种模态的输出质量AI 安全与对齐的实验:如何实验验证 AI 系统的安全性和对齐性?这是一个新兴且重要的研究方向。
附录附录 A:关键术语表

